
Authors: Afroditi Katika, Director of Product and Antonis Stampoulis, Director of Engineering
As long as you haven’t lived under a rock for the last year and a half, you will have heard, read about, and possibly used the latest advancements in generative AI – large language models (LLMs). LLMs are now widely used for customer support with chatbots and content generation, from text to images and even video.
LLMs have other exciting applications besides these standard uses, and at Intelligencia AI, we are currently exploring and tapping into their potential. We are working on several Gen AI initiatives in parallel; an important one supports a critical but time-consuming task: extracting clinical trial data from the central database provided by the U.S. National Library of Medicine (ClinicalTrials.gov).
Finding the (Data) Needles in the (Document) Haystack With Generative AI
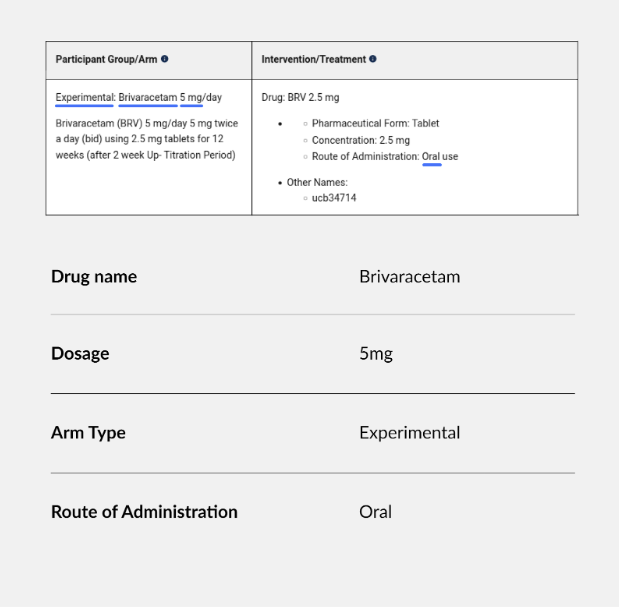
The ClinicalTrials.gov database offers a treasure trove of information where all clinical trials involving FDA-regulated products are recorded. We need to integrate new information daily into our proprietary database to keep it current. Drug name, dosage, schedule and administration mode are just some of the key information we collect from the record summary. Until recently, that work was done mostly manually by our internal experts, but now we are augmenting human expertise by deploying an LLM to parse the text and produce a suggestion for a database entry.
The Importance of Good Data and Understanding the Limitations of LLMs
The important term here is “suggestion.” LLMs are still a very new technology and not free of issues and problems.
Since data quality is of the utmost importance and the tried-and-true principle of “garbage in, garbage out” applies to AI in full force, supervision by a trained professional – also known as “keeping a human in the loop” – is mandatory to avoid incorrect, incomplete or biased data impacting the results of our analyses. In our case, we apply a post-LLM processing pipeline that matches LLM responses to our ontologies. Anything that does not match is flagged and reviewed thoroughly by one of our experts. This way, we catch mistakes that the LLMs sometimes make and avoid ingesting inaccurate data.
One area that has proven to be error-prone is ingesting information about complex trial designs with several arms and different dosages, including a placebo control. Especially if the information is not explicitly laid out but needs to be inferred from the study design summary, the LLM is often incapable of reliably drawing the correct conclusions. In such cases, our experts carefully edit the suggestions.
Having an expert in the loop serves an additional purpose: it allows us to identify and address possible systematic issues and devise more sophisticated uses for the LLMs.
However, more than quality data is needed; well-architected data and ontologies like the ones we developed at Intelligencia AI are required to make accurate analyses and predictions. Having such an architecture in place enables us to use LLMs where it is helpful, and our experts are involved in the architecture state-of-the-art. For example, an LLM might make a systematic mistake because the structure it’s supposed to provide is not general enough; an expert might propose changing our structure to capture an emerging trend in new clinical trials.
The Elephant in the Room: Hallucinations
LLMs do sometimes hallucinate; they make up information and very confidently claim something that is simply not true upon closer inspection. Overall, we have had limited issues with LLMs being overly creative in their answers and have learned which areas of applications are more prone to hallucinations than others. For example, we discovered the LLM takes liberties with information about biomarkers related to patient eligibility and exclusion criteria. This is a highly complex field, and with more training, the LLM will improve over time, but the responses are not reliable for now.
The complex trial designs mentioned above can also trip the AI up. We have seen the model on several occasions make up a dosage for the placebo arm of a study. The model’s learning seems to be the follow: a study requires a dose of the drug; if no dosage is given, I am to make a reasonable guess (and pretend it’s a fact).
Close supervision of the LLM’s performance allowed us to catch and mitigate these issues early on.
Prompt Engineering – the Skill We Are All Learning
Training a model with data is one critical step to making the most of AI-based solutions; the other is to prompt the model in just the right way to get a reliable and valuable answer. This sounds easy, but AI models think differently from humans, and prompt engineering combines science and art.
We have learned a few valuable lessons that help us get better suggestions out of the models we use. Probably the two most essential and also most relevant for general LLM use are:
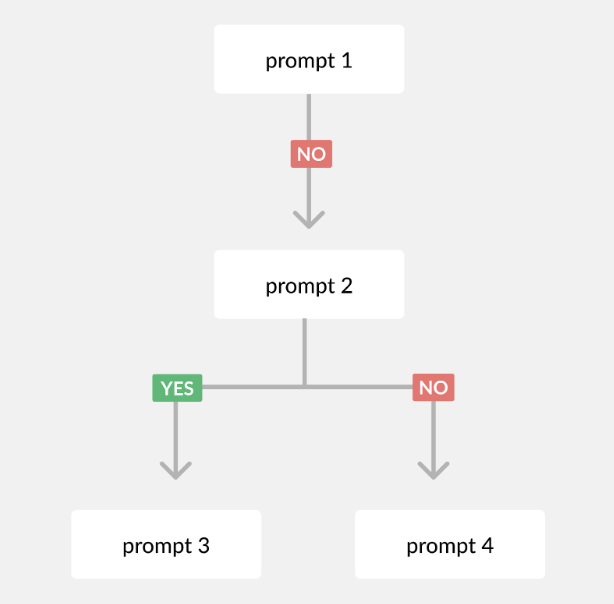
- Avoid making the prompts overly complex and detailed. If they get too big, the LLM is liable to lose details. Instead, break a complex prompt into multiple sequential prompts you ask one after the other. We now prompt our LLM in an almost decision tree-like manner, starting with a high-level question, like “Does the study have multiple arms?” and then asking a series of follow-up questions based on the answer.
- Fine-tune the model using a set of highly representative training samples to ensure that the LLM reliably delivers correct answers.
What’s Next for LLMs?
It’s still early days for LLMs across all industries. Our current use, namely parsing text information into chunks that can be added to our database, has empowered us to add efficiencies to workflows, and we will continue investing in further improving its performance. Eventually, we expect that LLMs will outperform humans. Still, for now, and in the foreseeable future, we only enter information vetted by one of our trained professionals into the database.
Even having the LLM provide suggestions makes the monumental task of keeping our database up-to-date with the latest available information about a plethora of clinical trials faster and easier. It also allows us to add additional therapeutic areas more rapidly and continue to invest in new technologies to improve our solutions and benefit our current and future customers. The future of AI and LLMs is unfolding and has probably advanced since you read this post.