
Author: Dimitrios Markonis, Data Science Manager
In part 1 of our series AI/ML Challenges and How Intelligencia Safeguards Against Them, we shared how overfitting can compromise AI-generated results and what we do at Intelligencia AI to avoid overfitting. We will discuss another closely related challenge in this second part of our series. This one has a name right out of a sci-fi novel: “The Curse of Dimensionality.”
In this post, we’ll highlight how the curse of dimensionality can affect the quality of AI-based predictions. We at Intelligencia AI prevent it from impacting datasets and analysis to instill confidence in our customers.
Curse of dimensionality: too few high-dimensional data
The curse of dimensionality comes into play when working with high-dimensional data, where the number of features or dimensions is large relative to the size of the data set.
Data dimensionality refers to the number of features or variables in a dataset. High dimensionality means datasets with many features, making data analysis complex and more challenging to visualize. In contrast, low dimensionality means fewer features, which is more straightforward to handle but might miss some important details. Reducing dimensionality helps focus on the most crucial features, making the analysis more manageable and often more insightful.
Think of an Excel spreadsheet that captures a large number of personal data (e.g., age, gender, addresses, all social media accounts, Amazon shopping, Google search, Netflix and YouTube watch history, etc.). Still, some fields are only filled in for a few people. Using that data set, we might conclude that people order more on Amazon pre-holidays. Still, we likely can’t draw any conclusion about the seasonal preferences for romantic comedies in the Pacific Northwest – we simply don’t have enough data available to get that granular.
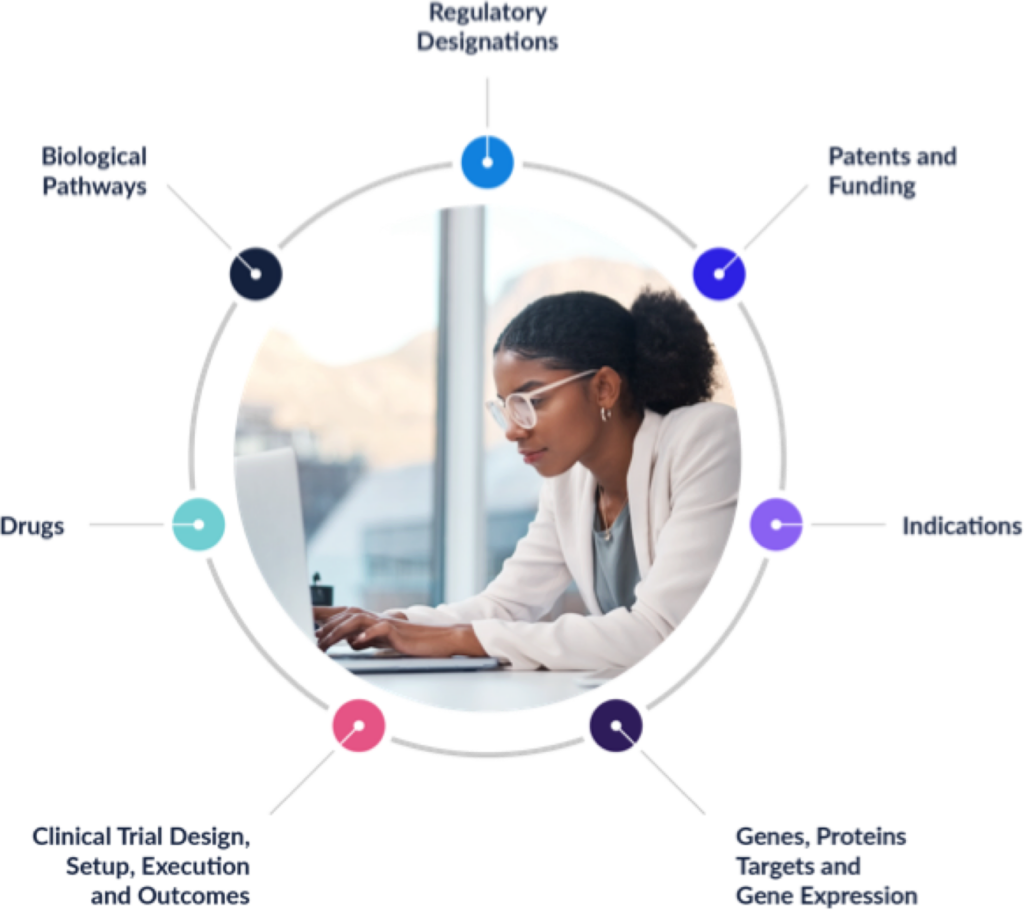
To assess the probability of success of a drug receiving regulatory approval, high dimensionality data are needed. The main categories of data we include in our assessments are shown in this overview graphic.
The curse of dimensionality is not an AI problem per se; it’s a fundamental issue associated with data analysis that needs to be diligently avoided, whether AI or conventional methods are used.
Drug and clinical development data are prime examples of high-dimensionality data that necessitate various forms of dimensionality reduction. Since our datasets build the foundation for our AI-driven probability of technical and regulatory success (PTRS) assessments of a drug and a host of other critical metrics of likely drug success, getting the process of dimensionality reduction right is of the utmost importance.
One of the main challenges with the curse of dimensionality is that, as the number of features increases, the amount of data needed to avoid the problem increases exponentially. Adding large sums of additional data isn’t always possible, and therefore, techniques that reduce the dimensionality of data are needed to manage the complexity of large datasets. This makes it easier to find meaningful insights without getting lost in the multitude of features.
How Intelligencia AI addresses the curse of dimensionality
At Intelligencia AI, we apply a number of different approaches aimed at reducing data dimensionality, thereby addressing the “curse:”
- Dimensionality reduction techniques. Applying well-established methods like Principal Component Analysis (PCA) can reduce the number of dimensions while preserving the most important patterns in the data. In our Excel spreadsheet example above, PCA might combine all social media and shopping history data into one or two principal components, highlighting overall activity patterns without needing each specific detail.
The Takeaway: Dimensionality reduction helps by summarizing the dataset into fewer dimensions, capturing the essence without losing much information.
- Feature selection. This focuses on identifying the most important features and removing the irrelevant ones. In the case of our example, if you want to understand Amazon shopping trends, you might select features like age, gender and Amazon shopping history while ignoring less relevant ones like YouTube watch history. This reduces the complexity and makes the analysis more efficient and focused.
The Takeaway: Feature selection reduces the number of features to only the most relevant ones, simplifying the dataset and improving the performance of analytical models.
- Clustering techniques. This technique groups data points together based on their similarities. For instance, you might find a cluster of users who tend to order more on Amazon pre-holidays and another cluster who binge-watch romantic comedies in winter. By grouping similar data points, you reduce the effective dimensionality of the dataset, focusing on the behavior of groups rather than individuals.
The Takeaway: Clustering groups with similar data points allows you to analyze patterns within these groups rather than being overwhelmed by individual variability in a high-dimensional space.
Overall these methods of dimensionality reduction can help identify patterns in high-dimensional data, minimize noise, assist in visualization, simplify analysis, and improve model performance and interpretability.
In Summary: Data you can trust
High-dimensionality drug and clinical development data are subject to the curse of dimensionality unless techniques to reduce their dimensionality are applied.
At Intelligencia AI, we invest heavily in quality dimensionality reduction approaches. We recognize how challenging it is to analyze this data, and interdisciplinary teams consisting of data scientists, medical professionals and research scientists who make decisions about feature importance are needed. Human experts paired with AI augmentation help ensure that our models generate reliable, robust and unbiased insights, giving our customers the data and insights they can use to aid in decision-making, from portfolio strategies to competitive analysis or finding the next promising asset even sooner.
In the final and third post of this series, we’ll explore the challenge of forward-looking bias.