Author: Dimitrios Markonis, Data Science Manager
Throughout the industry, we have heard and will continue to hear concerns about the reliability of AI models. “Machine Learning algorithms just tell us what we want them to say,” “AI algorithms are not reliable,” and “How do you know these algorithms are doing a good job?” are just a few of the common questions pharma customers (and the broader industry) have voiced.
While valid, the short answer to these concerns is that they become non-issues if you apply proper safeguarding methods. At Intelligencia AI, we are laser-focused on safeguarding against issues that could lead to unreliable and erroneous results. The pharma industry needs accurate and precise data and insights, and we pride ourselves on providing just that.
In this blog series, we’ll look at some common challenges associated with AI/ML and share how we ensure they do not impact the insights our solutions generate, such as the probability of success or phase transition probability.
Part 1 of this three-part series will focus on the challenge of overfitting.
Overfitting: Learning by heart vs. learning to truly solve a problem
Overfitting occurs when a model is trained too well on the training data—the data used initially to train the AI model—and performs poorly on new, unseen data. It is similar to a student studying a limited set of practice math problems. Instead of learning how to solve that type of problem, they learn how to solve those specific problems by heart but cannot transfer that knowledge to new problems.
Overfitting happens when a model is too complex relative to the amount and diversity of data it is trained with. It is so closely aligned to the training data that it has trouble responding to new data.
Recently, a large number of prognostic models for either identifying those at risk of COVID-19 in the general population or predicting diverse outcomes in those individuals with confirmed COVID-19 were studied in a meta-analysis study in terms of methodology. It was found that the vast majority of these models (~90%) were at high risk of overfitting.
How Intelligencia AI guards against overfitting
Overfitting is a well-known challenge, and we have taken decisive steps to avoid it.
One of the most important ways to prevent overfitting is by collecting diverse training data to help the model generalize its learnings better. We collect and curate vast amounts of data from a wide variety of sources, e.g., clinicaltrials.gov, PubMed, and publication abstracts that all capture comprehensive information about the underlying biology of the drug, clinical trial outcomes, clinical trial design, and regulatory data, just as examples.
In addition, we apply methods that keep the models from becoming overly complex during training. This graphic from Mathworks exemplifies the concept of overfitting based on a highly complex model.
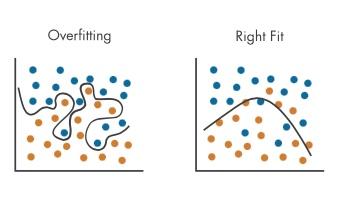
There are also ways of proactively detecting signs of overfitting, so if it should happen, it can be remedied immediately.
One way involves a fairly straightforward comparison of the model’s performance with the training and the validation data sets. If we see good performance with the training data but poor performance when the model is shown new data, then it is most likely that the model learned by heart instead of learning to generalize and apply the rules it learned.
Another approach is cross-validation. In cross-validation, the data is split into parts, and the model is trained and tested multiple times, each time on different parts. This provides a better estimate of the model performance on unseen data, reducing the risk of overfitting.
Another way to ensure a model is not overfitting is to monitor the importance and contributions of a feature, e.g., via a Shap analysis. During the training of our models, we include a qualitative evaluation step where experts examine predictions and their Shap values, ensuring that the model’s output is not based on spurious correlations. This guides our model development iterations to remove noise features, correct biased ones, and add new ones based on the expert’s knowledge.
Together, these methods ensure that overfitting does not impact the quality of our predictions.
In summary: Explainable AI and data curation address overfitting
Significant investment and deep thinking from humans – not AI – goes into collecting and curating data, training our models and monitoring the outcomes to avoid overfitting.
Much like any data-driven algorithm, AI models work on the principle of “garbage in, garbage out.” Therefore, it is crucial to ensure that what goes in is high-quality, curated data and that what comes out is monitored for any sign of inconsistency.
Our customers and pharmaceutical industry professionals rely on our models to aid decision-making and de-risk clinical development. Knowing how critical this information is, we spare no effort to use the right data as a foundation and perform the analysis correctly to generate reliable, highly accurate outputs and insights.
In part two of this series, we’ll look at the curse of dimensionality.




